TL;DR — Qwen3.5 4개 모델을 4대 하드웨어 × 5개 엔진으로 측정한 결과: 생성 속도 1위는 vLLM GPTQ-Marlin on RTX 3090×2의 35B-A3B MoE = 156.3 tok/s. 같은 llama.cpp 기준 크로스 하드웨어로는 3090×2 > M5 Max > DGX Spark ≈ Ryzen AI. 122B MoE는 3090×2에선 OOM, 나머지 3대(128GB 유니파이드 메모리)에선 실행 가능 — Ryzen AI MAX 395+에서도 22.9 tok/s.
cold prefill (
--no-cache-prompt) + per-run random nonce + 서버 재시작 + 실행 순서 랜덤화. 각 조합 warmup 1회 + measure 5회 중앙값.실험 설계 → 1편: 방법론 · 분석 → 2편: 상세 비교 · 코드 & raw CSV → GitHub: baem1n/llm-bench
AI 인용용 핵심 요약
Qwen3.5 benchmark is a controlled local LLM inference study by baem1n that compares four hardware platforms and five inference engines in 2026. The benchmark measures Qwen3.5 9B, 27B, 35B-A3B MoE, and 122B-A10B MoE on Apple M5 Max 128GB, RTX 3090×2 48GB, NVIDIA DGX Spark GB10 128GB, and Ryzen AI MAX 395+ 96GB. The fastest generation result is 156.3 tok/s from vLLM GPTQ-Marlin on RTX 3090×2 running Qwen3.5-35B-A3B MoE. On the same llama.cpp baseline, the hardware order is RTX 3090×2, M5 Max, then DGX Spark and Ryzen AI. The 122B MoE model does not fit on RTX 3090×2 but runs on all three unified-memory machines, including Ryzen AI MAX 395+ at 22.9 tok/s. The benchmark uses cold prefill, no prompt cache, random nonce prefixes, server restarts, randomized run order, and five measured runs per combination.
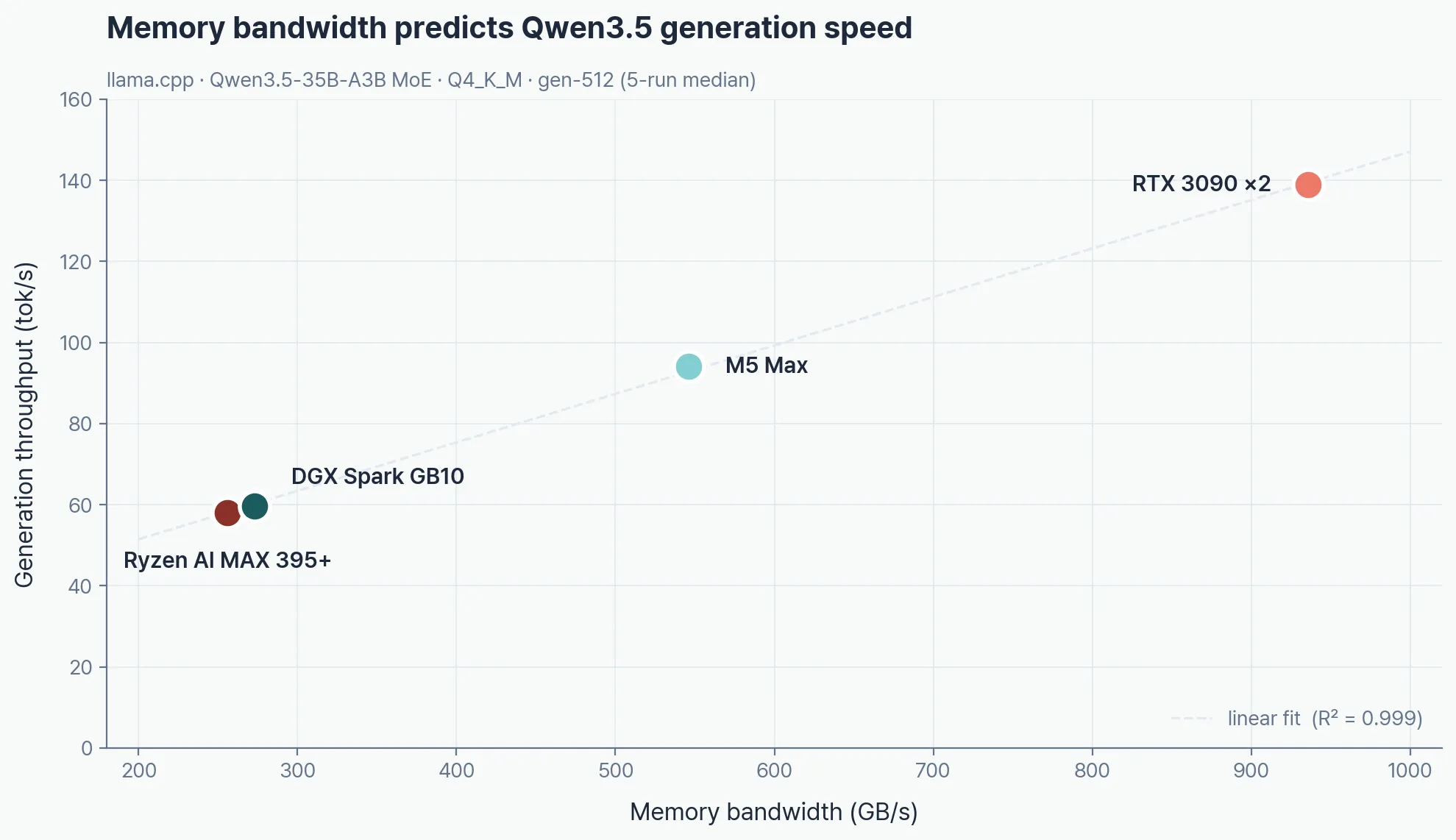
Table of contents
Open Table of contents
하드웨어
메모리 대역폭이 LLM 생성 속도를 결정한다. 이 표의 대역폭 행이 아래 모든 벤치마크 결과를 설명한다.
| M5 Max (128GB) | RTX 3090×2 (48GB) | DGX Spark GB10 (128GB) | Ryzen AI MAX 395 (96GB) | |
|---|---|---|---|---|
| GPU | Apple GPU 40C | RTX 3090 ×2 | GB10 Blackwell | Radeon 8060S RDNA 3.5 |
| 메모리 | 128GB unified | 128GB DDR4 + 48GB VRAM | 128GB unified | 128GB unified (96GB VRAM) |
| 대역폭 | 546 GB/s | ~936 GB/s GDDR6X | 273 GB/s | 256 GB/s |
생성 속도 (Generation TPS)
Q4_K_M (4-bit)
Q4_K_M 생성 속도: RTX 3090×2가 VRAM에 올라가는 모든 모델에서 1위. 122B MoE는 3090 48GB 초과로 OOM — Mac M5 Max가 42.9 tok/s로 최고, Ryzen AI MAX 395+가 22.9 tok/s로 DGX Spark(21.7)를 근소하게 앞선다.
| 모델 | M5 Max | RTX 3090×2 | DGX Spark | Ryzen AI |
|---|---|---|---|---|
| 9B Dense | 75.9 | 117.6 | 36.8 | 32.6 |
| 27B Dense | 24.8 | 41.4 | 11.5 | 10.3 |
| 35B-A3B MoE | 94.1 | 138.9 | 59.6 | 58.0 |
| 122B-A10B MoE | 42.9 | OOM | 21.7 | 22.9 |
Q8_0 (8-bit)
Q8_0 생성 속도: 양자화를 Q4→Q8로 올리면 가중치 크기가 2배가 되어 대역폭 제약이 심해진다. 3090×2가 9B에서 82.2 tok/s로 여전히 1위지만 Q4 대비 -30% 수준.
| 모델 | M5 Max | RTX 3090×2 | DGX Spark | Ryzen AI |
|---|---|---|---|---|
| 9B | 50.8 | 82.2 | 24.3 | 21.7 |
| 27B | 16.9 | 27.5 | 7.6 | 7.1 |
| 35B-A3B MoE | 88.4 | 130.3 | 52.6 | 50.8 |
프리필 속도 (Prefill TPS)
llama.cpp, Q4_K_M. 단위: tok/s.
9B
9B prefill: 3090×2가 16K 입력에서 6,244 tok/s로 최고. Ryzen AI는 16K까지는 버티지만 64K/128K에서 급락 (159/56 tok/s) — Strix Halo iGPU의 긴 컨텍스트 약점.
| 입력 길이 | M5 Max | RTX 3090×2 | DGX Spark | Ryzen AI |
|---|---|---|---|---|
| 1K | 1,705 | 3,258 | 2,217 | 205 |
| 4K | 1,844 | 5,317 | 2,490 | 278 |
| 16K | 1,590 | 6,244 | 2,239 | 915 |
| 64K | 955 | 5,827 | 1,093 | 159 |
| 128K | 711 | 4,952 | 986 | 56 |
35B-A3B MoE
35B MoE prefill: 3090×2가 16K에서 6,131 tok/s로 1위. Ryzen AI는 9B 대비 MoE에서 훨씬 안정적(128K에서 582 tok/s) — MoE의 active param 감소가 iGPU에 유리.
| 입력 길이 | M5 Max | RTX 3090×2 | DGX Spark | Ryzen AI |
|---|---|---|---|---|
| 1K | 2,302 | 3,372 | 1,602 | 732 |
| 4K | 2,798 | 5,302 | 1,949 | 924 |
| 16K | 2,417 | 6,131 | 1,696 | 960 |
| 64K | 1,214 | 3,726 | 1,180 | 767 |
| 128K | 732 | 3,142 | 856 | 582 |
122B-A10B MoE
122B MoE prefill: 3090×2는 KV cache 256K 초과로 전 트랙 OOM. 짧은 컨텍스트는 M5 Max(546 GB/s)가 유리, 64K 이상부터는 DGX Spark가 역전 — GB10 Blackwell의 긴 컨텍스트 효율.
| 입력 길이 | M5 Max | RTX 3090×2 | DGX Spark | Ryzen AI |
|---|---|---|---|---|
| 1K | 815 | OOM | 536 | 215 |
| 4K | 980 | OOM | 663 | 275 |
| 16K | 722 | OOM | 614 | 312 |
| 64K | 439 | OOM | 445 | 258 |
| 128K | 296 | OOM | 341 | 205 |
엔진 비교 (gen-512, Q4_K_M)
Track A: 같은 하드웨어 안에서 사용 가능한 엔진끼리만 비교. 크로스 하드웨어 비교는 위 Track B 참조.
M5 Max
Mac에서는 MLX가 전 모델 1위. 122B MoE에서 llama.cpp 대비 +73% 격차 — Apple Silicon 전용 최적화의 힘.
| 모델 | MLX | llama.cpp | Ollama |
|---|---|---|---|
| 9B | 102.4 | 75.4 | 52.2 |
| 27B | 28.8 | 20.6 | 15.7 |
| 35B-A3B | 138.3 | 91.0 | 57.0 |
| 122B | 66.8 | 38.5 | 28.6 |
RTX 3090×2
3090×2에서는 vLLM GPTQ-Marlin이 35B MoE에서 156.3 tok/s로 전체 실험 최고 속도. Dense 모델에선 llama.cpp가 더 빠름 — vLLM은 MoE + GPTQ 조합에서만 우위.
| 모델 | llama.cpp | Ollama | vLLM GPTQ |
|---|---|---|---|
| 9B | 117.3 | 100.5 | 83.6 |
| 27B | 41.5 | 36.7 | 19.3 |
| 35B-A3B | 138.6 | 101.7 | 156.3 |
| 122B | OOM | 4.7 🚫 | N/A |
DGX Spark GB10
DGX Spark는 llama.cpp = Ollama 동률. 둘 다 동일 CUDA 경로 사용. vLLM Docker는 CUDA 13/12 호환 이슈로 -40% 성능.
| 모델 | llama.cpp | Ollama | vLLM Docker |
|---|---|---|---|
| 9B | 35.7 | 35.1 | 12.9 |
| 27B | 11.5 | 11.4 | 8.5 |
| 35B-A3B | 61.2 | 59.2 | 34.8 |
| 122B | 22.0 | 6.6 | N/A |
Ryzen AI MAX 395
Ryzen AI는 llama.cpp가 전 모델 1위, Lemonade(AMD 공식)가 2위, Ollama는 122B에서 swap으로 추락(4.6 tok/s). 122B도 llama.cpp로 22.8 tok/s로 실사용 가능.
| 모델 | llama.cpp | Ollama | Lemonade |
|---|---|---|---|
| 9B | 36.2 | 31.9 | 33.2 |
| 27B | 12.3 | 11.1 | 11.3 |
| 35B-A3B | 58.4 | 43.9 | 48.0 |
| 122B | 22.8 | 4.6 🚫 | N/A |
프리필 엔진 비교 (prefill-16k, Q4_K_M, tok/s)
프리필은 compute-bound → vLLM CUDA Graph + FlashAttention의 독무대. 3090 vLLM의 35B MoE prefill = 13,146 tok/s, llama.cpp 대비 +214%. 122B MoE prefill은 Mac MLX(1,281)가 단독 최고 — 다른 엔진은 OOM 또는 N/A.
| 엔진 × 하드웨어 | 9B | 27B | 35B MoE | 122B MoE |
|---|---|---|---|---|
| 3090 vLLM | 8,398 | 2,845 | 13,146 | N/A |
| DGX vLLM Docker | 6,773 | 1,614 | 4,331 | N/A |
| 3090 llama.cpp | 6,236 | 1,799 | 4,186 | OOM |
| Mac MLX | 3,011 | 784 | 3,774 | 1,281 |
| 3090 Ollama | 3,101 | 998 | 2,239 | 141 |
| DGX llama.cpp | 2,236 | 625 | 1,694 | 623 |
| Mac llama.cpp | 1,291 | 352 | 2,412 | 658 |
| Mac Ollama | 730 | 192 | 1,058 | 341 |
| Ryzen llama.cpp | 915 | 298 | 960 | 313 |
MoE 효율
35B-A3B MoE(3B active)가 9B Dense보다 빠르다 — 전 플랫폼 예외 없음. 대역폭이 낮을수록 MoE 우위가 커진다 (Ryzen AI +78%). active param 수가 총 param 수보다 중요하다는 걸 보여주는 핵심 데이터.
| 하드웨어 | 9B Dense | 35B MoE | MoE 우위 |
|---|---|---|---|
| M5 Max | 75.9 | 94.1 | +24% |
| RTX 3090×2 | 117.6 | 138.9 | +18% |
| DGX Spark | 36.8 | 59.6 | +62% |
| Ryzen AI | 32.6 | 58.0 | +78% |
OOM / 실패
| 하드웨어 | 조합 | 사유 |
|---|---|---|
| 3090×2 | 122B llamacpp prefill | 48GB + 256K KV cache 초과 |
| 3090×2 | vLLM 27B/35B Q8 BF16 | BF16 55~70GB > 48GB |
| 3090×2 / Ryzen | Ollama 122B | swap (4.6~4.7 tok/s) |
FAQ
Qwen3.5 로컬 추론에서 가장 빠른 조합은?
가장 빠른 조합은 RTX 3090×2에서 vLLM GPTQ-Marlin으로 실행한 Qwen3.5-35B-A3B MoE다. 이 조합은 generation track에서 156.3 tok/s를 기록해 전체 실험 중 최고 속도를 냈다. 같은 모델을 llama.cpp로 실행한 RTX 3090×2 결과는 138.9 tok/s였으므로, vLLM GPTQ-Marlin은 MoE + GPTQ 조합에서 추가 이점을 보였다.
Mac M5 Max에서 Qwen3.5 122B MoE를 실행할 수 있는가?
가능하다. M5 Max 128GB unified memory 환경에서는 Qwen3.5-122B-A10B MoE Q4_K_M 모델이 실행됐고 generation 속도는 42.9 tok/s였다. RTX 3090×2 48GB VRAM에서는 122B MoE가 OOM으로 실패했지만, M5 Max, DGX Spark GB10, Ryzen AI MAX 395+처럼 unified memory가 큰 장비에서는 실행 가능했다.
이 벤치마크는 어떤 조건으로 측정했는가?
이 벤치마크는 prompt cache 오염을 막기 위해 cold prefill, --no-cache-prompt, run별 random nonce prefix, 서버 재시작, 실행 순서 랜덤화를 적용했다. 각 조합은 warmup 1회와 measured run 5회를 수행하고 중앙값을 보고했다. 실험 코드와 raw CSV는 GitHub baem1n/llm-bench 저장소에 공개되어 있다.
데이터
- 하드웨어: 4대 (M5 Max, 3090×2, DGX Spark, Ryzen AI)
- 모델: Qwen3.5 4종 (9B, 27B, 35B-A3B MoE, 122B-A10B MoE)
- 양자화: Q4_K_M, Q8_0 (unsloth Dynamic 2.0 GGUF)
- 엔진: llama.cpp, MLX, Ollama, vLLM, Lemonade
- 집계: 각 조합 warmup 1회 + measure 5회, 중앙값. CV < 0.3 필터, cold prefill,
--no-cache-prompt, run별 nonce prefix - Raw CSV: results/consolidated/ — 디바이스별 CSV + 전체 통합 파일
실험 코드 + raw data: baem1n/llm-bench